

Cloud Computing core concepts
Migrating to the cloud? Get a general overview of cloud computing and the key concepts that you should consider when making a move to the cloud.
{kind=link}
What is Cloud Computing?
Cloud computing is a service providing access to hardware and software resources on demand.
Key Cloud Concepts
According to NIST definition of cloud computing, it has five characteristics
There are five key cloud characteristics: on-demand self-service, broad network access, resource pooling, rapid elasticity, and measured service. A solution must exhibit these five characteristics to be considered a true cloud solution.
On-demand self-service
Povision computing capabilities as needed automatically without requiring human interaction with service provider
For example, consumers are able to help themselves and decide which services to subscribe to, and how much to invest—all at the swipe of a credit card or using an online payment system. An IT department can now quickly purchase more resources on-demand to cater to sudden spikes in user load.
Broad network access
Capabilities are available over the network and accessed through standard mechanisms.
Cloud services hinge on the Internet’s infrastructure, and as such provide a ubiquitous availability of services as long as there is an Internet connection. An USA-based executive can perform his roles during business travel, accessing his company’s online resources hosted in Ireland via the Internet connection in Singapore.
Resource pooling
The provider's computing resources are pooled to serve multiple consumers using a multi-tenant model, with different resources dynamically assigned and reassigned according to demand.
The combined computational power of large amounts of physical and virtual servers provides a cost-effective pooling of resources. Multitenancy solutions have enabled several organizations to share the same cloud computing resources without worrying about data spilling into each other’s logical boundaries.
Rapid elasticity
Capabilities can be elastically provisioned and released, sin some cases automatically, to scale rapidly outwardand inward with demand
Cloud services leverage on technologies such as server and storage virtualization to rapidly meet the rise and fall of user load and service demand. A newly launched business expecting 10,000 customers will be able to handle an unexpected load of 1 million customers without worrying about the need to purchase or set up new servers in short notice. Elasticity also improves the utilization of the cloud resources.
Measured service with pay-per-use
Resource usage can be monitored, controlled, and reported, providing transparency for both the provider and consumer of the utilized service
Given the above characteristics, it works for both service providers and consumers to have an easy-to-measure payment scheme mimicking the power utilities and cable television model—pay-per-use. At the appropriate price point, pay-per-use has the potential to alleviate the need for forecasting and planning of resources, and reduce wastage of overheads.
Cloud Deployment Models
Following this lesson the student will know the different deployment models available and will be able to give an understanding and distinction between Public, Private and Hybrid Clouds.
There are four cloud deployment models: public, private, community, and hybrid. Each deployment model is defined according to where the infrastructure for the environment is located.
From a deployment point of view and inspired by NIST’s cloud definition, four categories of cloud deployment models can be distinguished
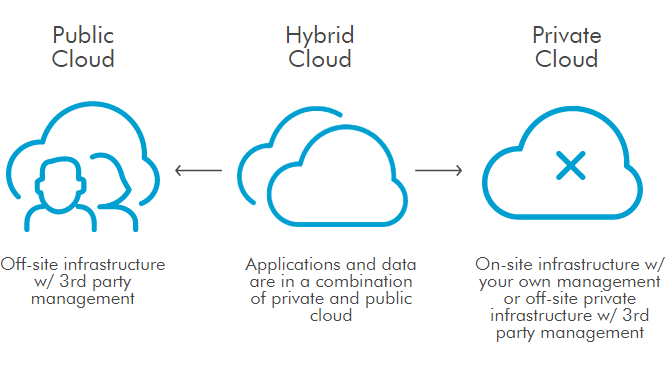
Public Clouds
the services of public clouds are available for public use and can
be accessed through the Internet. Public clouds are generally provided by large
companies like : Google, Amazon, Microsoft and IBM,
Private Clouds
the private cloud infrastructure is operated for the only use by an exclusive organization. The cloud can be managed by the organization or by a
third-party. Also the infrastructure can be on-premises or off-premises,
Community Cloud
the Community Cloud infrastructure is provided for exclusive use by a specific community of users from organizations that have shared concerns. It can be managed, owned and operated by one or more organizations in the community, by third parties or by some combination of them. It can be on-premises or off-premises,
Hybrid Clouds
hybrid clouds are mostly a composition of two models of deployments (public,private or community) that remain unique entities, but are bounded together by standardized or proprietary technologies that enable data and application portability,
Service Models
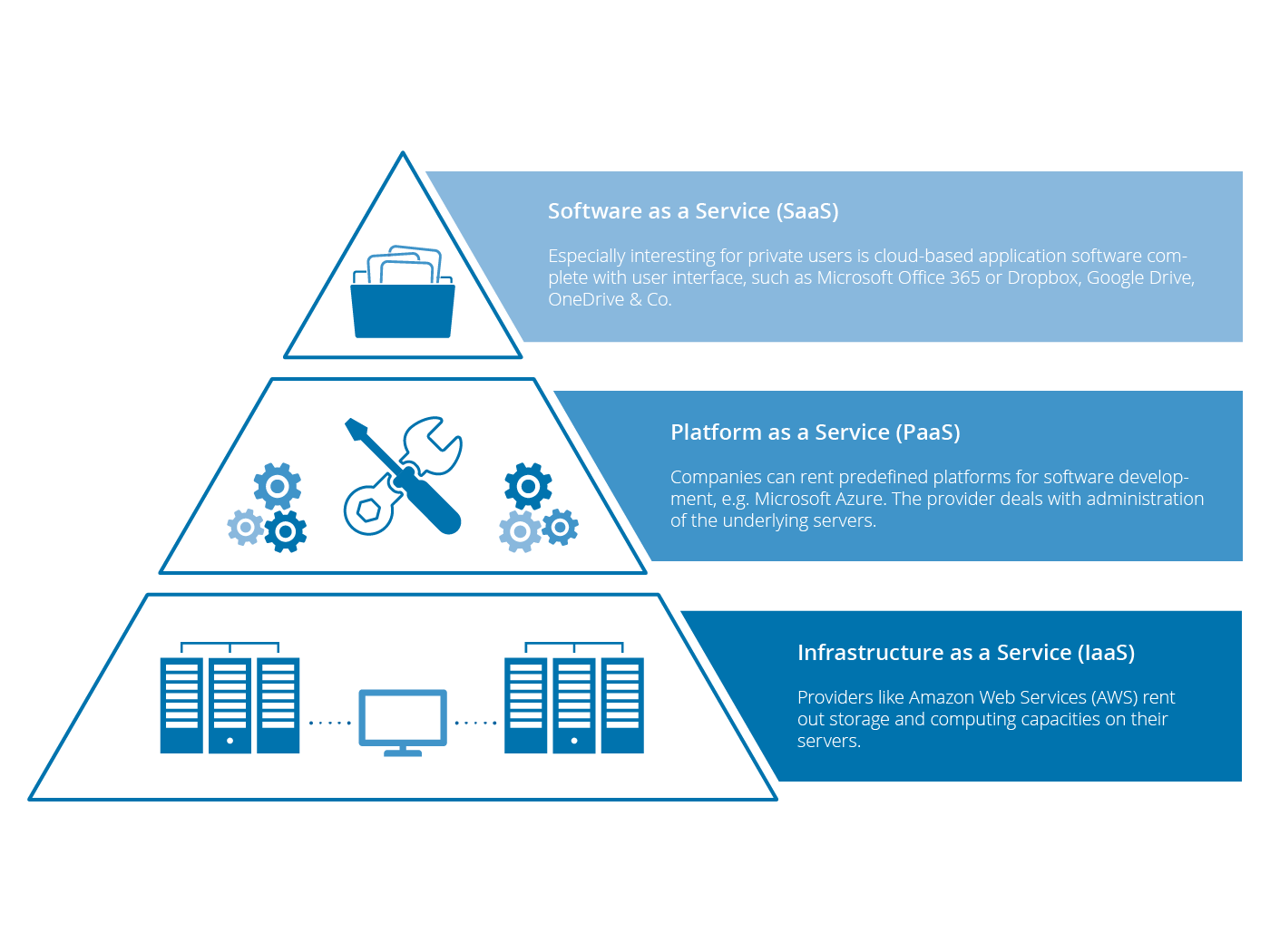
Cloud computing services come in three types: SaaS (Software as a Service), IaaS (Infrastructure as a Service), and PaaS (Platform as a Service).
Each of the cloud models has its own set of benefits that could serve the needs of various businesses. Choosing between them requires an understanding of these cloud models, evaluating your requirements, and finding out how the chosen model can deliver your intended set of workflows.
The following is a brief description of the three types of cloud models and their benefits.
1. SaaS
SaaS or Software as a Service is a model that gives quick access to cloud-based web applications. The vendor controls the entire computing stack, which you can access using a web browser. These applications run on the cloud and you can use them by a paid licensed subscription or for free with limited access.
SaaS does not require any installations or downloads in your existing computing infrastructure. This eliminates the need for installing applications on each of your computers with the maintenance and support taken over by the vendor. Some known examples of SaaS include Google G Suite, Microsoft Office 365, Dropbox, etc.
2. PaaS
Platform as a Service or PaaS is essentially a cloud base where you can develop, test, and organize the different applications for your business. Implementing PaaS simplifies the process of enterprise software development. The virtual runtime environment provided by PaaS gives a favorable space for developing and testing applications.
The entire resources offered in the form of servers, storage, and networking are manageable either by the company or a platform provider. Google App Engine and AWS Elastic Beanstalk are two typical examples of PaaS. PaaS is also subscription-based and gives you flexible pricing options depending on your business requirements.
3. IaaS
IaaS or Infrastructure as a Service is basically a virtual provision of computing resources over the cloud. An IaaS cloud provider can give you the entire range of computing infrastructures such as storage, servers, networking hardware alongside maintenance and support.
Businesses can opt for computing resources of their requirement without the need to install hardware on their premises. Amazon Web Services, Microsoft Azure, and Google Compute Engine are some of the leading IaaS cloud service providers.
To sum up, SaaS, PaaS, and IaaS are simply three ways to describe how you can use the cloud for your business.
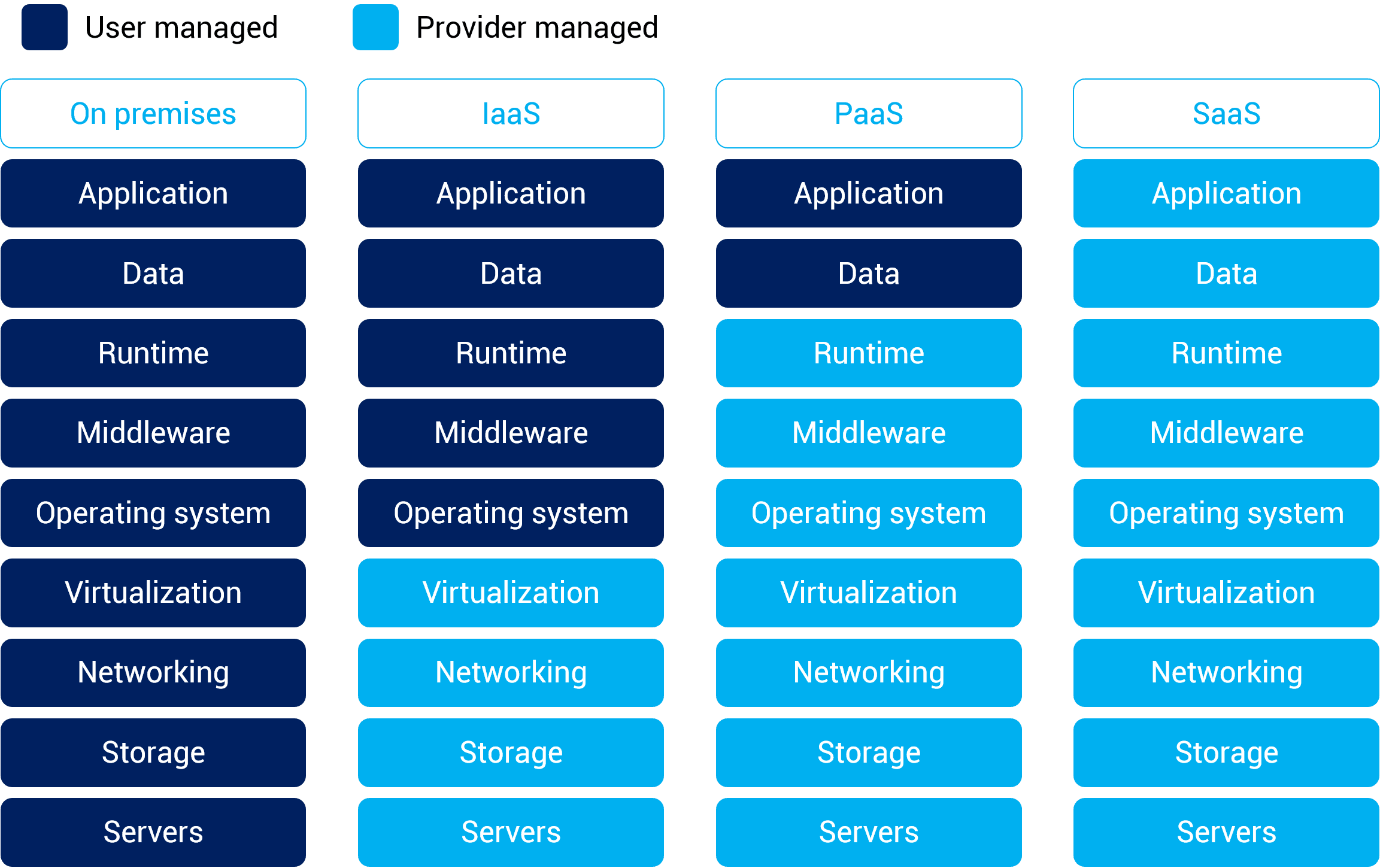
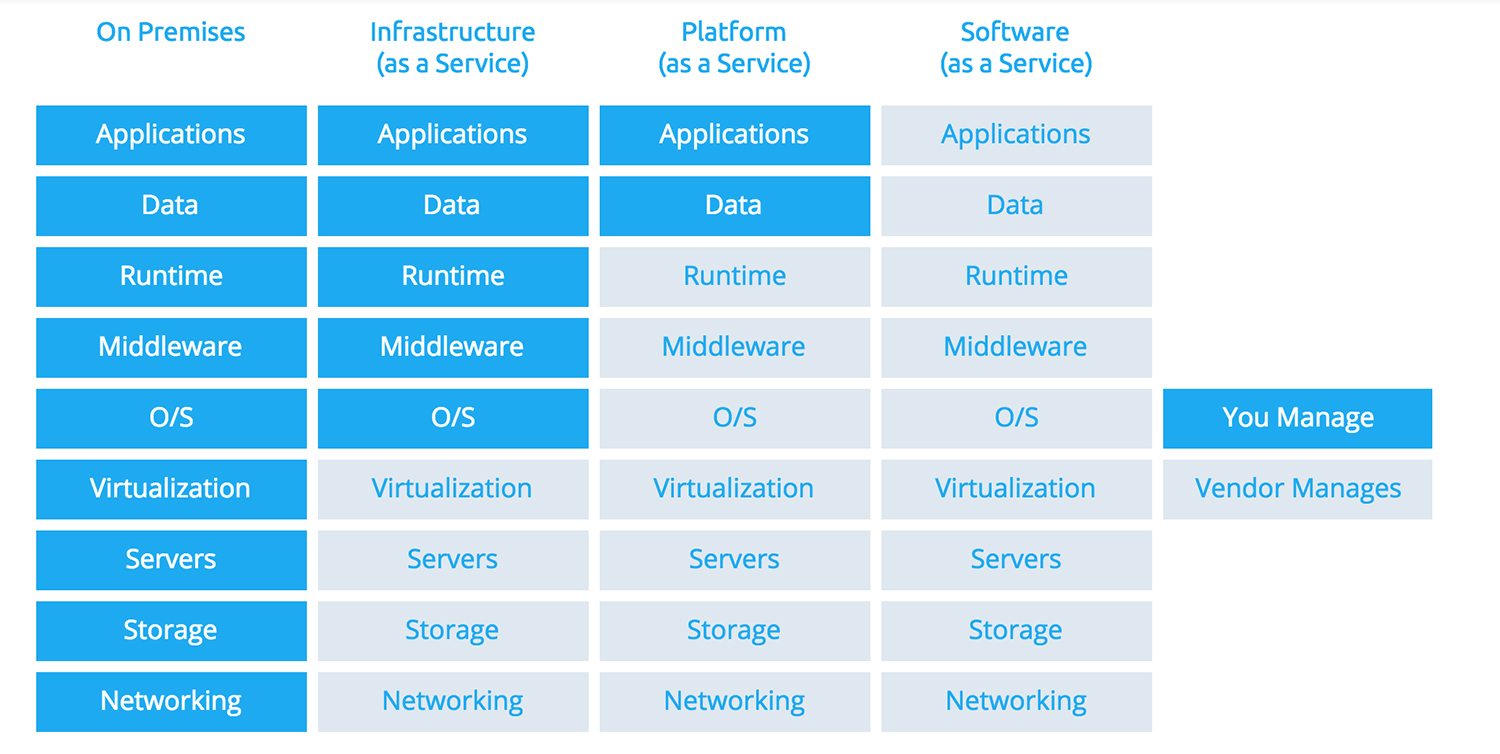
- IaaS: cloud-based services, pay-as-you-go for services such as storage, networking, and virtualization.
- PaaS: hardware and software tools available over the internet.
- SaaS: software that’s available via a third-party over the internet.
- On-premise: software that’s installed in the same building as your business.
Below you find a visual representation of what the aspects do that are managed by the supplier or the organisation as a user for the deifferent cloud service models:
Cloud Computing Reliability Indicators
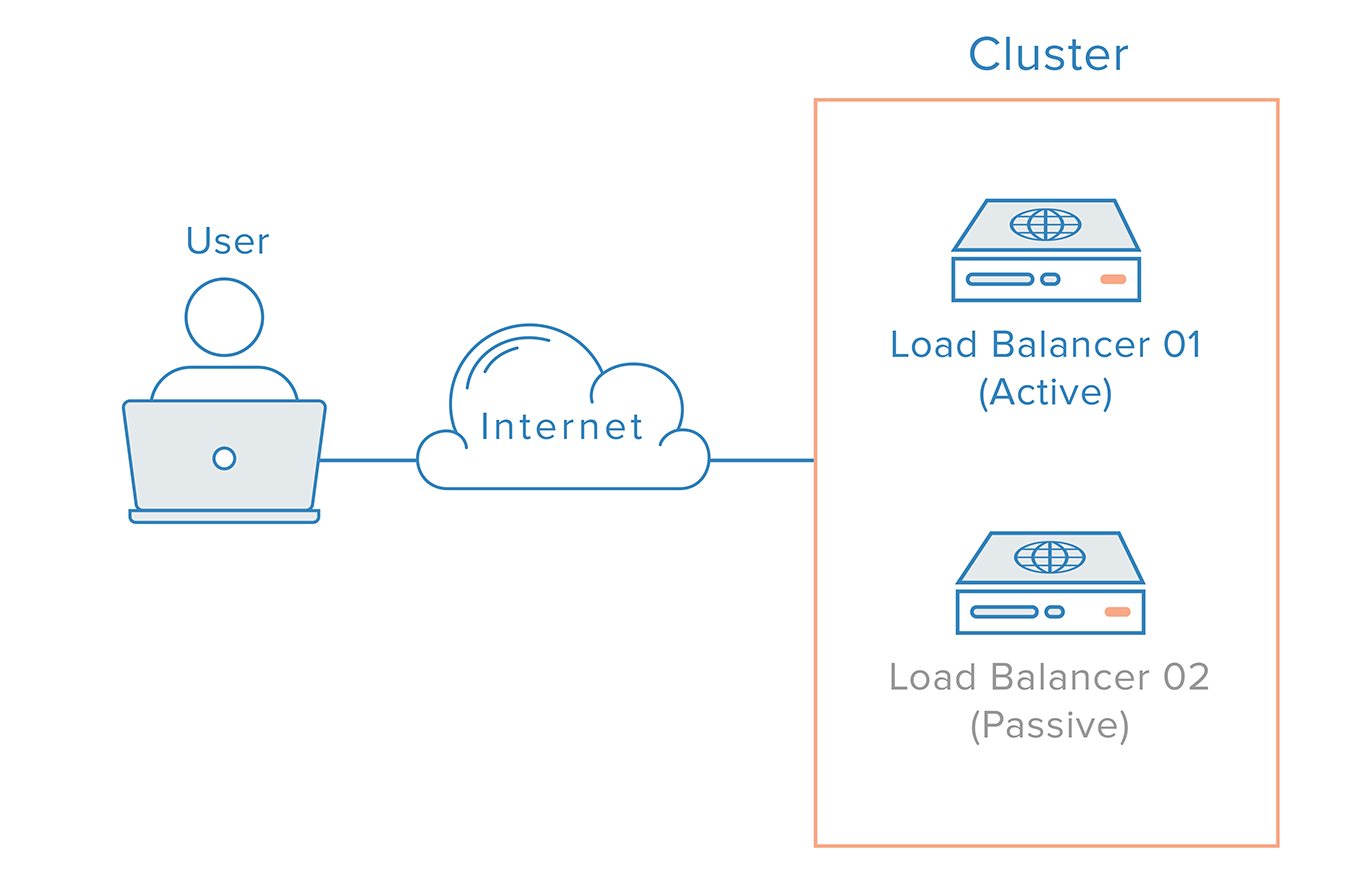
High availability
Computing environments configured to provide nearly full-time availability known as high availability systems.
Such systems typically have redundant hardware and software that makes the system available despite failures.
Well designed high availability systems avoid having single points-of-failure. So when failures occur, the failover process moves processing performed by the failed component to the backup component. The more transparent that failover is to users, the higher the availability of the system.
Disaster recovery
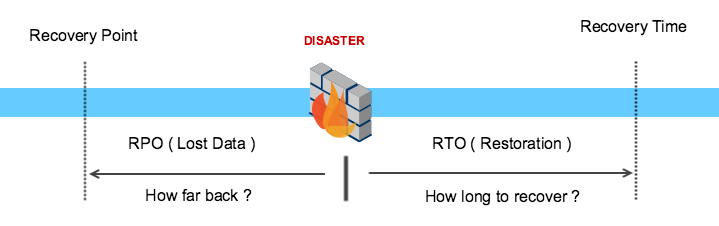
Disaster recovery (DR) involves a set of policies, tools and procedures to enable the recovery or continuation of viral technology infrastructure and systems.
Disaster recovery should indicate the key metrics of recovery point objective (RPO) and recovery time objective (RTO).
The Recovery Point Objective (RPO) determines the maximum acceptable amount of data loss measured in time. For example, the maximum tolerable data loss is 15 minutes. In this case, a backup has to be performed each 15 minutes.
The Recovery Time Objective (RTO) determines the maximum tolerable amount of time needed to bring all critical systems back online. This covers, for example, restore data from back-up or fix of a failure. In most cases this part is carried out by system administrator, network administrator, storage administrator etc.
Fault Tolerance
Fault tolerance describes how a cloud vendor will ensure minimal downtime for services provided
Fault tolerance is the property that enables a system to continue operating properly in the event of the failure of (or one or more faults within) some of its components. The architecture has to be free of SPOFs ( Single Point Of Failure).
Resiliency
The capacity to recover quickly from failure.
Resiliency is the ability of a server, network, storage system, or an entire data center, to recover quickly and continue operating even when there has been an equipment failure, power outage or other disruption.
Data center resiliency is a planned part of a facility’s architecture and is usually associated with other disaster planning and data center disaster-recovery considerations such as data protection. The adjective resilient means "having the ability to spring back."
Data center resiliency is often achieved through the use of redundant components, subsystems, systems or facilities. When one element fails or experiences a disruption, the redundant element takes over seamlessly and continues to support computing services to the user base. Ideally, users of a resilient system never know that a disruption has even occurred.
For example, if an ordinary server’s power supply fails, the server fails -- and all of the workloads on that server become unavailable until the server is repaired and restarted (or the workloads can be restarted on another suitable server). If the server incorporates a redundant power supply, the backup supply keeps the server running until a technician can replace the failed power supply.
Scalability
Scalability is the property of a system to handle a growing amount of work by adding resources to the system.
Infrastructure scalability handles the changing needs of an application by statically adding or removing resources to meet changing application demands as needed. In most cases, this is handled by scaling up (vertical scaling) and/or scaling out (horizontal scaling).
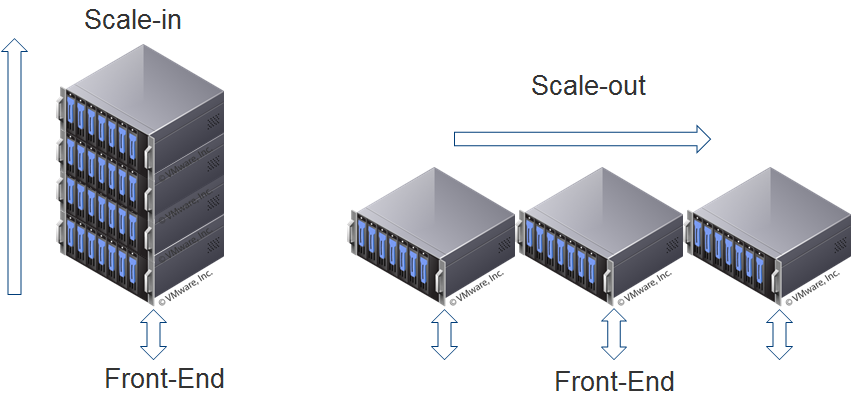
Scale-up or Vertical Scaling
Scale-up is done by adding more resources to an existing system to reach a desired state of performance. For example, a database or web server needs additional resources to continue performance at a certain level to meet SLAs. More compute, memory, storage, or network can be added to that system to keep the performance at desired levels. When this is done in the cloud, applications often get moved onto more powerful instances and may even migrate to a different host and retire the server it was on. Of course, this process should be transparent to the customer. Scaling-up can also be done in software by adding more threads, more connections, or in cases of database applications, increasing cache sizes. These types of scale-up operations have been happening on-premises in datacenters for decades. However, the time it takes to procure additional recourses to scale-up a given system could take weeks or months in a traditional on-premises environment while scaling-up in the cloud can take only minutes.
Scale-out or Horizontal Scaling
Scale-out is usually associated with distributed architectures. There are two basic forms of scaling out: Adding additional infrastructure capacity in pre-packaged blocks of infrastructure or nodes (i.e. hyper-converged) or use a distributed service that can retrieve customer information but be independent of applications or services. Both approaches are used in CSPs today along with vertical scaling for individual components (compute, memory, network, and storage) to drive down costs. Horizontal scaling makes it easy for service providers to offer “pay-as-you-grow” infrastructure and services.
Elasticity
In cloud computing, elasticity is defined as "the degree to which a system is able to adapt to workload changes by provisioning and de-provisioning resources in an autonomic manner, such that at each point in time the available resources match the current demand as closely as possible. Elasticity aims at matching the amount of resource allocated to a service with the amount of resource it actually requires, avoiding over- or under-provisioning.
Let us illustrate elasticity through a simple example of a service provider who wants to run a website on an IaaS cloud. At moment T0, the website is unpopular and a single machine (most commonly a virtual machine) is sufficient to serve all web users. At moment T1, the website suddenly becomes popular, for example, as a result of a flash crowd, and a single machine is no longer sufficient to serve all users. Based on the number of web users simultaneously accessing the website and the resource requirements of the web server, it might be that ten machines are needed. An elastic system should immediately detect this condition and provision nine additional machines from the cloud, so as to serve all web users responsively. At time T2, the website becomes unpopular again. The ten machines that are currently allocated to the website are mostly idle and a single machine would be sufficient to serve the few users who are accessing the website. An elastic system should immediately detect this condition and deprovision nine machines and release them to the cloud.
CAPEX vs OPEX
Capital expenditure or capital expense (CAPEX) is the money an organization or corporate entity spends to buy, maintain, or improve its fixed assets, such as buildings, equipements, ..
Operational expenditure or OPEX is an ongoing cost for running a product, business or a system.
What makes Cloud so interesting is it lets you trade CAPEX for OPEX. So instead of having to invest heavily in data centers and infrastructure, in the cloud, you can just pay only when you consume resources, and pay only for how much you consume.
References:

The DevOps Bootcamp 🚀 Newsletter
Join the newsletter to receive the latest updates in your inbox.

What is a Service Mesh and Why Should you Care About It
Paid
Members
Public
In this article, we’ll explain what a service mesh is, why it’s needed, and lay out the service mesh startup landscape as it exists today.
Introduction to Service Meshes on Kubernetes
Paid
Members
Public
What is a service mesh? How does it work? Why would you want a service mesh in your application and what can it provide? Get a quick overview of service mesh and Kubernetes.